Beam's GC(1)!
erlang
At the last post of my blog I did some test between gen_server and gen_msg. After the
test when the result came out I was wandering why beam take fifty times of time
to finish the job when mailbox growth five times bigger.
I couldn’t find the answer. I read some of the internal doc of erts, but still
no idea. This is the first time I couldn’t find a direction on solving some question.
So I tried to ask some superhero of the internet at stackoverflow. Then a superhero
helped me here.
It was all GC’s fault to make the process much slower then we expected. The only
one meet with the time cost we expected it test8. The only reason why this happend
is that only test8 neither send message to its mailbox nor create any new term.
So the process did not allocated any memory during its running, so it needs no GC.
That’s why it ran so fast, more than four hundred faster than others which send
send message and create new terms.
When process A send a message to process B, A need to allocated memory of its own
heap to put the message needed to be send. Then A put a pointer to B’s message
queue. The pointer point to the message on A’s heap. The memory on A’s heap stored
the message will be merge into B’s heap by process A’s GC. So When there is too
many message in B’s heap, B will GC.
When we change the state of a gen_server like this:
handle_info({job, Job}, State) ->
Result = done_job(Job),
NewState = [{Job, Result}|State],
{noreply, NewState};
We actually creat a new tuple {Job, Result}, so beam need to allocated some memory
on this process’s heap to store this new tuple. If we change too many times, there
will be too many new tuples on process’s heap, then the process will do the GC
for more frequently, then cost more time.
Above are the two reasons why gen_server cost more time then test8.
Then I start wandering who do the process GC, when the GC happens. Then I found
this.
First question: Who do the process GC? The scheduler. And when the scheduler
do the process GC, it cost this process’s reduction. And once the scheduler start
GC, it cann’t stop. That meams if a process’s heap is too big, it can block other
process on this scheduler’s run queue.
Second question: When the GC happens? It happens before the process scheduled in.
So if one process’s GC cost more than 2000 reductions, after GC this process will
scheduled out, back to the end of the run queue and wait for another loop.
There are two types of GC in beam: Generational GC and Reference-counted GC.
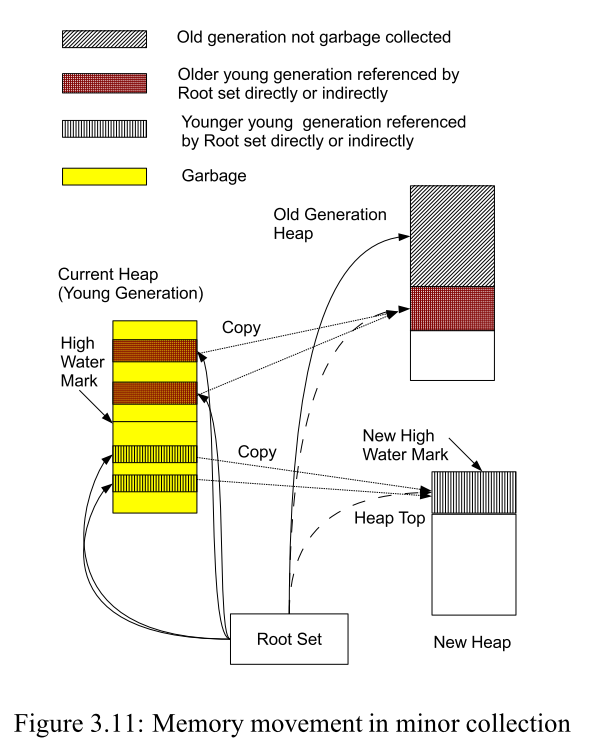
Generational GC used for GC process’s private heap. There are two generations in
heap: young generation and old generation. All new object are created in young
generation. When the young generation is full, Beam will do a minor collection,
it put every usefull object’s collection times plus one. After that Beam will
copy the object which collection times more than one to the old generation, and
copy the object which collection times equals one to the younger young generation.
Then delete the old young generation.
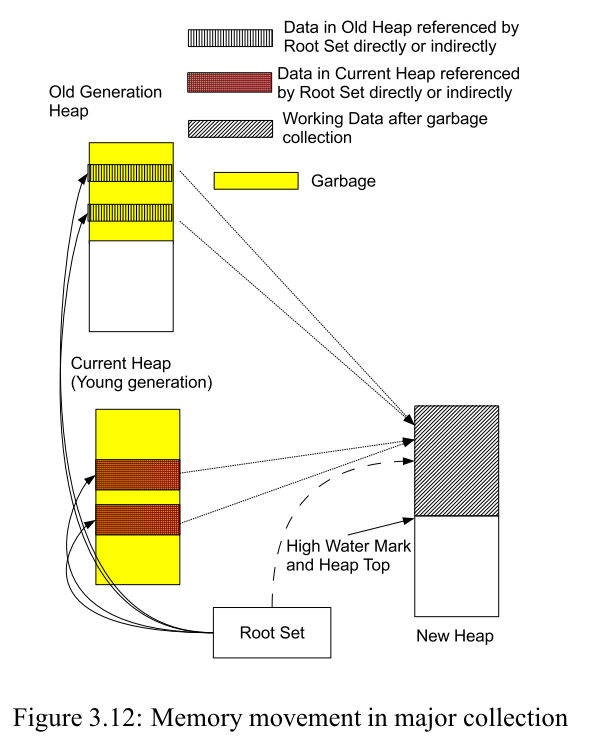
When old generation is full, Beam will do a major collection. It plus one of
the collection times of every usefull object in old generation and young generation.
Then copy all objects which collection times more than one to the younger old generation.
And delete the older young generation and the older old generation.
Reference-counted GC used for public heap. When some process use the object in
public heap. The object’s reference-count will plus one, an reference to this
object will create in the process’s private heap. When the process deallocated
the reference of the object during its GC, the reference-count of the object will
minus one, if reference-count is zero right now, then the object will be deallocated
from the public heap.
Hahaha, have fun guys! :)